
计算图任务调度与优化策略
上班好忙,好久没写blog了,这周末难得清闲,但发现自己已经电子游戏阳痿了,不如来写写博客吧~
在正定私募工作的这半年,学到了很多金融知识,也积累了很多技术实践,这次就来讲讲我花了大笔时间研究的东西——计算图调度与优化。
背景是这边有计算大量表达式的需求,表达式先被解析为为AST,而且这些表达式可能有公共子表达式(AST节点复用),子表达式又有子表达式层层嵌套(依赖关系与计算次序),所以表达式计算任务可以被表示为DAG。
说来有趣,当时乾象投资面试的时候(挂了),直接给我来了道计算图调度的题目。我之前做后端做性能优化,但是真没做过任何计算图的相关方向,当时费老大劲还被提示好几次才做出来。也正是因为这次经历,痛定思痛,对计算图有了更多的认知,也有了深入思考的动力。
写在前面
这篇文章并不是一篇算法或数据结构的科普文章,而是对计算图在工程上应用的思考与总结。如果有可能,希望这篇文章能尽可能地拓展读者的思路~内容专门做过脱敏,所以缺少例子,可能不那么容易读懂。
计算图有特别特别多的优化策略,还没有很细的研究,以后如果有需求会慢慢补充。
基本概念
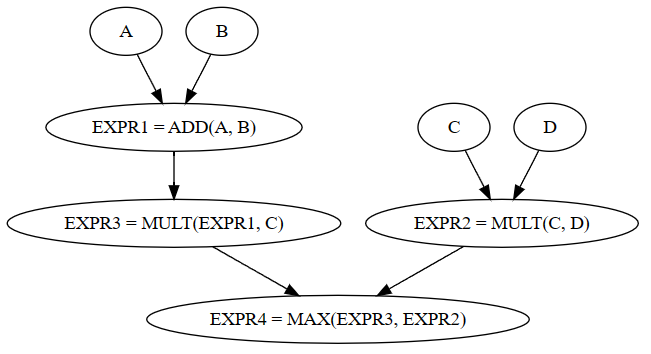
首先弄明白计算图是啥,这里有个表达式 X=MAX((A+B)*C, C*D) ,翻译成计算图就是下面这个,按计算次序表明了表达式和子表达式的依赖关系的DAG。这里这个和AST就比较像,因为没有别的表达式,有别的表达式的话节点之间可能会复用,从而连接成一个图,AST就表示不了这个任务啦。
这里的概念其实我根据业务里具体的任务做的抽象,可能不是很通用🤷,看看就完了:
- 任务:业务中真正的计算任务
- 节点:计算图中的调度单元,一个节点可能包括多个任务
- 执行线程:用于进行节点的计算,执行节点内的任务
- 调度器:负责规划节点的执行,分配计算任务
计算图调度的任务本质上是从无入度节点开始遍历计算图,所有节点被遍历完成就是计算任务全部完成。
建图
我这里的需求在建图的时候已经拿到了经过拓扑排序的任务序列,节点也有上游依赖信息,这里就很简单了。先简单扫描一遍,把任务封装进节点,拿到任务和节点的映射,再反向扫描一遍,把任务的节点加入到上游任务的节点的下游列表中,一个简单的基于链表的图就建好了。当然,用邻接表什么的也行,视需求选用数据结构,毕竟数据结构不是重点。
调度
我这里有一个调度器线程去分配任务,而不是使用相对常见且简单的生产消费者模式,这是因为生产消费者模式并不能很好fit任务需求。消费者去竞争队列,往往会增加平均等待时间,更何况我的目标是使用100甚至200个CPU核心去加速计算任务,竞争可能会非常明显,哪怕用CAS也可能会有较大的失败率。更何况,任务是有优先级的,在执行时我们总是希望那一瞬间是高优而非低优任务被执行。而生产者队列中高优的任务可能会晚于低优任务被添加,不便于按优先级完成任务(如果把队列做成优先队列那平均等待时间就爆了)。后面会提到是如何使用调度器+执行器的模型解决这些问题的。
这里还有一个问题,那为什么不用GPU呢?1. 因为显存真不够,这个调度器一分钟调用一次,耗时要控制在100ms,而且每次调用需要计算一遍整个计算图,需要使用高至500GB的内存(后面的大型计算任务甚至要2TB内存)。如果用GPU,需要分布式计算,而且得把显存凑够,否则还得按需从内存拷贝到显存再按需释放,实现麻烦程度就大了去了;2. 算子很复杂,可以确定的是没有算子库可以用,大部分算子需要写CUDA去实现,学习成本和维护成本不太能接受。大概就这两个原因了。
节点的开销
节点的开销对调度器是很重要的,虽然真实的时间开销需要实际执行后才能知道,但是可以基于节点内任务的复杂度去估计节点的时间开销,每个节点都需要保存自己的开销信息。
节点优先级
节点优先级,或者称为权重,总希望当前可用任务中权重最高的节点先被执行。我这里权重的定义是对节点从该节点出发直到终止节点所经过节点的开销总和的最大值。这样的定义的目的是让开销最重的链路(因为依赖关系导致不能并行加速)最先被执行,从而尽可能缩短完成整个计算图的耗时,这是优先级定义的首要考量。
执行器流程
- 尝试从固定地址轮询获取节点
- 执行节点内任务
- 向通知队列发送完成信息
调度流程
维护一个基于权重的大根堆,首先把开始节点(无入度)全部放进去。流程:
- 启动循环
- 判断是否大根堆为空且没有节点在执行器内执行,是则终止循环,否则继续
- 循环从大根堆中取出权重最大节点并交给空闲执行器,直到大根堆为空或无空闲执行器
- 尝试从通知队列中获取,如果失败,回到步骤2
- 更新完成节点所有孩子节点的等待情况
- 获取所有上游就绪的孩子节点,如果没有,回到步骤2
- 讲获取到的孩子节点放入大根堆中,回到步骤2
这里还有一些优化方案会改变这个流程,下面会讲。
优化
这里的优化策略和我们具体的业务是息息相关的,所以大概读读,如果有启发最好。但是具体的业务内容那肯定是不能讲,只能写在内网的wiki上啦~
剪枝
我们这里业务需求中的计算图是要被多次计算的,并且每次计算时会有不同的参数,这些参数会决定本次计算有哪些表达式需要被计算,在计算图调度的语境下,就是有一些节点不需要被计算。
剪枝操作不是必要的,因为我们业务中的任务会自动跳过不需要执行的参数。但是为了降低调度开销,剪枝又是很重要的。这里的剪枝需要进行预处理。预处理会在建图之后反向扫描节点拓扑序列,计算每个节点及其后续所有节点计算条件的并集,调度时只需要判断参数是否满足条件集合,即可确认子图是否不需要被计算,从而完成剪枝。
需要修改调度流程,将7修改为:
7. 获取所有上游就绪且满足计算条件的孩子节点,如果没有,回到步骤2
节点内加速
对于计算图调度来说,每一个节点的执行效率都直接影响到整体的性能。尤其在金融领域,每一毫秒的时间都可能与大量的资金流转息息相关。因此,提高单个节点的执行速度变得至关重要。因为单个节点的加速,可以降低这个节点的时间开销,从而缩短计算图中的最长链路,缩短计算图内节点的平均权重。
这里的方案是为每个节点添加了一个拆分属性breakdown,并且用一个进度变量node_progress表示这个节点的完成情况。向执行器分配任务时,breakdown为10的节点就会被拆成10个任务去分发,调度器拿到的完成反馈也是10次,每次去更新下计数器,调度器发现进度满了就触发节点完成的处理逻辑。
另外也为了节点内加速设计了一套拆分逻辑,因为有些任务并不能完全并行完成,任务内可能包含一些步骤是必须串行处理的。最终的方案是把节点按任务的步骤拆分成并行节点和串行节点,这一步在建图计算breakdown的时候就完成。
需要修改调度流程,在4后面添加4.5:
4.5 更新节点的完成情况,如果breakdown未全部完成,则回到步骤2
节点合并
有一类表达式,比如 X=((A+B)*C)/D,每个计算都仅仅依赖上次的结果(ABC是变量,不是计算节点),这样的表达式在计算图中(如果子表达式没有被其它表达式复用)就是一个节点的链条。这样的链条必须串行执行,这就导致与其依次计算X的这些节点,不如把这些节点合并成一个节点,一次性调度和完成,消除调度带来的平均等待时间提升。
需要注意的是,进行了节点内加速(要求节点只有一个任务)的节点不能与其它节点进行合并。
不需要修改调度流程。
批量处理
为执行器队列设置一个有容量限制的队列,允许执行器队列内的任务一次性取出,然后按权重排序,按顺序一次性完成,而不是取一个做一个,降低队列竞争带来的开销。这里依赖了一个开源的ConcurrentQueue实现,支持bulk enqueue和dequeue。
这里其实是权衡了高优任务的平均等待时间与调度开销,在保证调度开销尽可能低的前提下高优任务尽可能先地被执行。队列容量越小,调度开销越大,但是高优任务的平均等待时间越低,所以需要把队列容量设置为一个合适的值。
需要修改执行流程,修改1和2:
1. 尝试轮询执行器队列,如果有节点元素,一次性全部取出
2. 遍历取出的所有节点,执行每个节点内的任务
需要修改调度流程,将3修改为:
3. 循环从大根堆中取出权重最大节点并交给空闲执行器,直到大根堆为空或不存在还有可用空间的执行器队列
流水线加速
这个和业务强相关,可以允许这次参数计算的图的计算完且不再被依赖的节点,计算下一次参数计算的任务。大幅扩大可用节点池,让执行器全程不闲下来。
比较敏感,由于保密原因不展开讲了

